안녕하세요, comalmot입니다.
오늘은, github에 있는 Fuzzing101 Repo에서 제시한 가이드라인을 따라가면서 풀어보도록 하겠습니다.
우선, 이번 Exercise 1에서는 Xpdf라는 프로그램을 대상으로 퍼징을 수행하게 됩니다.
테스트 환경
- OS : Ubuntu 20.04.2 LTS
- RAM : 4GB
- HDD : 32GB
- VMWare Workstation 16 Pro
우리가 퍼징을 통해 발견하게 될 CVE-2019-13288이 어떤 취약점인지 확인해봅시다.
CVE-2019-13288
CVSS Score : 4.3

Xpdf 4.0.01에서 Parser.cc의 Parser::getObj() 는 공격자가 의도적으로 제작한 파일을 통해 "무한 재귀"를 일으킬 수 있고, 공격자는 원격으로 DoS 공격을 할 수 있습니다. 라고 합니다.
우선 퍼저를 돌리고 나서 Crash 위치를 확인한 다음에, 자세히 리뷰해야 할 것 같네요.
https://github.com/antonio-morales/Fuzzing101/tree/main/Exercise%201
GitHub - antonio-morales/Fuzzing101: A GitHub Security Lab initiative https://securitylab.github.com/
A GitHub Security Lab initiative https://securitylab.github.com/ - GitHub - antonio-morales/Fuzzing101: A GitHub Security Lab initiative https://securitylab.github.com/
github.com
Exercise 링크입니다.
Xpdf 3.02 설치
우선 Exercise 1이기 때문에, AFL++를 빌드하고 설치하는 과정이 포함되어 있습니다.
오늘 이 글에서는 해당 과정은 생략하고 Xpdf 빌드 과정만 포함하여 글을 작성하도록 하겠습니다.
Exercise 1에서는 Xpdf 3.02 버전을 다운받고 빌드합니다.
우선 아래 명령어를 입력하여 Xpdf 3.02를 다운로드하고 빌드합니다.
# xpdf 다운로드
wget https://dl.xpdfreader.com/old/xpdf-3.02.tar.gz
tar -xvzf xpdf-3.02.tar.gz
# xpdf 빌드
cd xpdf-3.02
sudo apt update && sudo apt install -y build-essential gcc
./configure --prefix="$HOME/fuzzing_xpdf/install/"
make
make install
이제 정상적으로 빌드되었는지 테스트합니다.
테스트를 위해 몇 가지 pdf 샘플들을 다운로드하도록 하겠습니다.
cd $HOME/fuzzing_xpdf
mkdir pdf_examples && cd pdf_examples
wget https://github.com/mozilla/pdf.js-sample-files/raw/master/helloworld.pdf
wget http://www.africau.edu/images/default/sample.pdf
wget https://www.melbpc.org.au/wp-content/uploads/2017/10/small-example-pdf-file.pdf
아래 명령어를 입력하여, pdfinfo 바이너리가 정상적으로 동작하는지 확인합니다.
$HOME/fuzzing_xpdf/install/bin/pdfinfo -box -meta $HOME/fuzzing_xpdf/pdf_examples/helloworld.pdf
정상적으로 동작한다면, 아래와 같은 화면을 보실 수 있습니다.
만약 위와 같이 화면이 나오지 않으신다면, 빌드를 재시도해보시길 바라겠습니다.
본격적인 퍼징을 위해 Xpdf 다시 빌드하기
AFL++ 설치를 마치신 뒤에, 아래 명령을 통해 Xpdf를 다시 빌드합니다.
Xpdf를 다시 빌드하는 이유는 AFL의 컴파일러로 빌드를 해야 Coverage-guided fuzzer의 기능을 모두 사용할 수 있기 때문입니다. (여러 Mutated input에 대한 Code Coverage 등등..)
아래 명령을 통해 기존 Xpdf 빌드를 삭제하고, afl-clang-fast 컴파일러를 사용해 Xpdf를 빌드합니다.
# 기존 Xpdf 빌드 삭제
rm -r $HOME/fuzzing_xpdf/install
cd $HOME/fuzzing_xpdf/xpdf-3.02/
make clean
# afl-clang-fast 컴파일러로 Xpdf 빌드
export LLVM_CONFIG="llvm-config-11"
CC=$HOME/AFLplusplus/afl-clang-fast CXX=$HOME/AFLplusplus/afl-clang-fast++ ./configure --prefix="$HOME/fuzzing_xpdf/install/"
make
make install
이제 fuzzer를 실행합니다.
afl-fuzz -i $HOME/fuzzing_xpdf/pdf_examples/ -o $HOME/fuzzing_xpdf/out/ -s 123 -- $HOME/fuzzing_xpdf/install/bin/pdftotext @@ $HOME/fuzzing_xpdf/output-i 옵션은 입력 케이스가 있는 디렉토리입니다.
-o 옵션은 AFL++가 Input case를 mutation한 파일이 저장될 경로를 나타냅니다.
-s 는 사용할 랜덤 시드를 나타냅니다.
@@는 AFL이 각 입력파일 이름으로 대체할 자리 표시자 대상의 명령줄(?) 입니다.
그래서 위 명령줄을 해석하면,
$HOME/fuzzing_xpdf/install/bin/pdftotext <input-file-name> $HOME/fuzzing_xpdf/output 을 각각 다른 input 파일로 실행한다고 보시면 되겠습니다.
일단 퍼저를 돌리기(?)전에, pdftotext가 무얼하는 친구인지 찾아보겠습니다.
이름 그대로.. pdf를 text로 변환해주는 도구입니다. Xpdf에 포함되어있구요, 일단 Parser.cc에서 문제가 생긴 것을 보니 pdf를 파싱하다가 취약점이 나온 것 같네요..
일단 바로 퍼저를 돌려봅시다!
제 기준으로는 약 2분만에 saved crashes(unique crashes) 가 나왔네요!
out 디렉토리에 있는 crashes 디렉토리와 hangs 디렉토리를 확인해보면 아래와 같은 화면이 보입니다.

우리는 Crash에 있는 id:00000,sig:11,src:000000,time:86768,execs:18370,op:havoc,rep:16 이라는 친구를 볼겁니다.
이 친구는 pdf 파일이고, pdftotext에 넣어보면 Crash(Segmentation fault)가 나는 것을 확인할 수 있습니다.
먼저 해야 할 일은 어디서부터 시작되었는가(?) 입니다. 저는 id:~~ 라는 이름을 가진 crash를 일으키는 pdf를 crash1.pdf라는 이름으로 바꾸어주었습니다.
분석 시작
pwndbg를 사용해서 분석을 시작해봅시다.
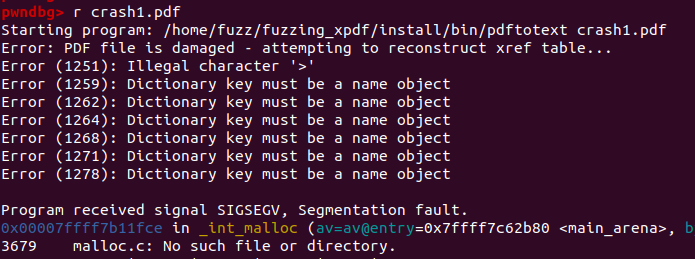
네.. Segmentation fault 입니다. 그 다음에, pwndbg의 기능 중 하나인 backtrace를 이용해 어디서부터 이 크래시가 왔나 살펴봅니다.
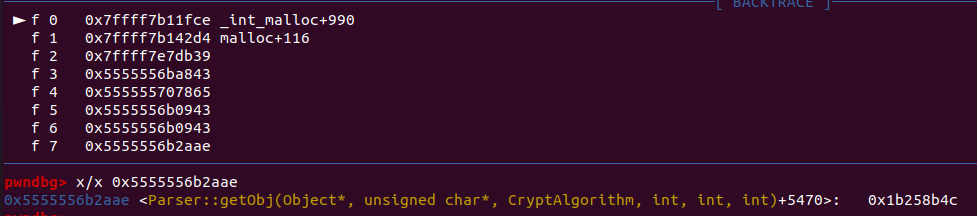
네, Parser::getObj() + 5470 이 시작이었군요!
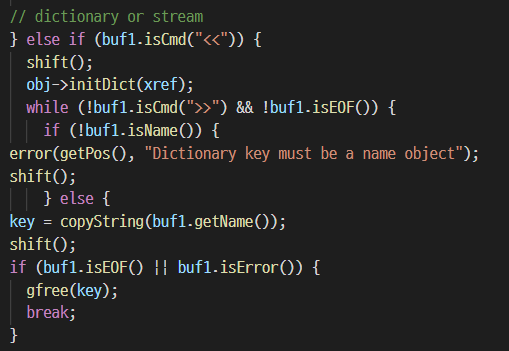
자, 그럼 breakpoint를 걸 부분을 찾게 되었습니다.
바로 Parser::getObj() + 5470 이겠죠!

이제 확인을 해봅시다.
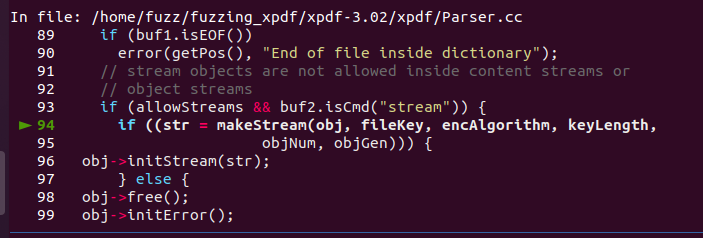
네, 의심되는 요소는 한개, makeStream 입니다. makeStream 함수의 어떠한 동작으로 인해 Segmentation fault가 났다고 추측할 수 있겠네요.
계속 들어가보겠습니다.
아직 이유는 모르겠으나, 계속 반복되는 느낌입니다. 실제로 반복이 되고 있었구요, makeStream의 bp를 해제하고 쭉 실행해보자 Segmentation Fault가 등장했습니다.. 또 makeStream의 인자로 들어오는 Object의 주소는 점점 증가를 했구요..
그럼 추측을 하나 할 수 있습니다.
모종의 이유(취약점이겠죠?) 로 인해 계속 일련의 과정들을 반복하다가, 어떤 이유로 인해 Segmentation fault가 등장했겠죠.
그러면 우선 bt 명령어로 어떠한 동작이 오고갔는지 확인해봅시다.
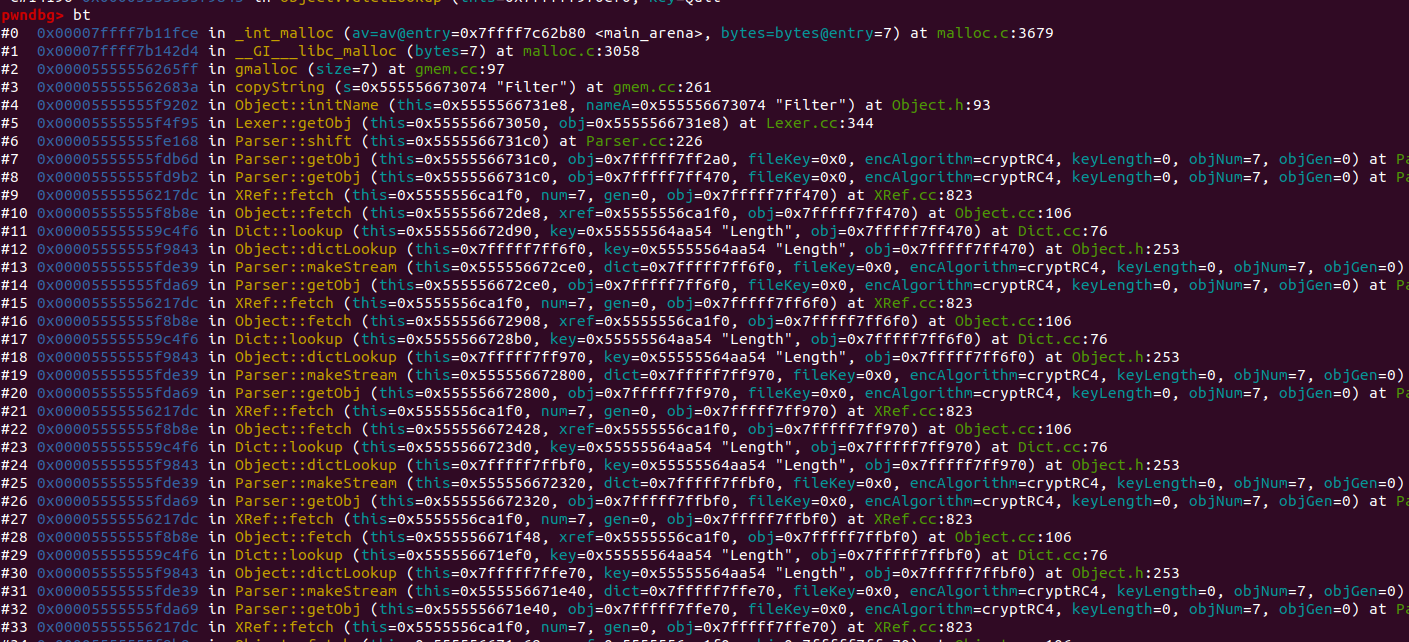
어이쿠.. 엄청나게 많네요.
우선 한 번 천천히 돌려보면서 모종의 동작이 자꾸 반복되는 것을 확인했습니다.

Parser::getObj -> Parser::makeStream -> Object::dictLookup -> Dict:lookup -> Object:fetch -> XRef::fetch 가 계속 반복되고 있었네요.
그 다음 마지막 뻥 터질때 쯤에는,

Parser::getObj -> Parser::getObj -> Parser::shift -> Lexer::getObj -> Object::initName -> copyString -> gmalloc -> __GI__libc_malloc -> _int_malloc 으로 가는 것을 확인할 수 있습니다.
소스를 확인해봅시다. (Xpdf 3.04 버전의 소스입니다)
우선 반복되었던 친구의 정체부터 알아내보죠.
아까 위에 올렸던 getObj의 소스입니다.
Object *Parser::getObj(Object *obj, Guchar *fileKey,
CryptAlgorithm encAlgorithm, int keyLength,
int objNum, int objGen) {
char *key;
Stream *str;
Object obj2;
int num;
DecryptStream *decrypt;
GString *s, *s2;
int c;
// refill buffer after inline image data
if (inlineImg == 2) {
buf1.free();
buf2.free();
lexer->getObj(&buf1);
lexer->getObj(&buf2);
inlineImg = 0;
}
// array
if (buf1.isCmd("[")) {
shift();
obj->initArray(xref);
while (!buf1.isCmd("]") && !buf1.isEOF())
obj->arrayAdd(getObj(&obj2, fileKey, encAlgorithm, keyLength,
objNum, objGen));
if (buf1.isEOF())
error(getPos(), "End of file inside array");
shift();
// dictionary or stream
} else if (buf1.isCmd("<<")) {
shift();
obj->initDict(xref);
while (!buf1.isCmd(">>") && !buf1.isEOF()) {
if (!buf1.isName()) {
error(getPos(), "Dictionary key must be a name object");
shift();
} else {
key = copyString(buf1.getName());
shift();
if (buf1.isEOF() || buf1.isError()) {
gfree(key);
break;
}
obj->dictAdd(key, getObj(&obj2, fileKey, encAlgorithm, keyLength,
objNum, objGen));
}
}
if (buf1.isEOF())
error(getPos(), "End of file inside dictionary");
// stream objects are not allowed inside content streams or
// object streams
if (allowStreams && buf2.isCmd("stream")) {
if ((str = makeStream(obj, fileKey, encAlgorithm, keyLength,
objNum, objGen))) {
obj->initStream(str);
} else {
obj->free();
obj->initError();
}
} else {
shift();
}
// indirect reference or integer
} else if (buf1.isInt()) {
num = buf1.getInt();
shift();
if (buf1.isInt() && buf2.isCmd("R")) {
obj->initRef(num, buf1.getInt());
shift();
shift();
} else {
obj->initInt(num);
}
// string
} else if (buf1.isString() && fileKey) {
s = buf1.getString();
s2 = new GString();
obj2.initNull();
decrypt = new DecryptStream(new MemStream(s->getCString(), 0,
s->getLength(), &obj2),
fileKey, encAlgorithm, keyLength,
objNum, objGen);
decrypt->reset();
while ((c = decrypt->getChar()) != EOF) {
s2->append((char)c);
}
delete decrypt;
obj->initString(s2);
shift();
// simple object
} else {
buf1.copy(obj);
shift();
}
return obj;
}보시다시피, 다양한 조건에 따라 동작을 하는 함수입니다.
그런데 재미있는 점은, getObj 함수 내에 makeStream을 실행하는 조건은 단 하나, stream이 있을 때 입니다. 그리고 buf2가 "stream" 인지 확인하고 있죠.
일단 crash를 낸 파일 안에 stream이 있는지 확인해보겠습니다.

네, 있군요. 하지만 endstream은 제외합니다. endstream을 따로 처리해주는 코드는 보이지 않았으니까요.
즉 offset 51A, 7D4에 있는 친구가 Crash를 내는 후보가 되겠습니다.
자, 이제 makeStream을 분석하기 전에, 위에 있는 주석이 보이네요

Stream objects are not allowed inside content stream or object streams.
스트림 오브젝트는 컨텐츠 스트림이나, 오브젝트 스트림 안에 들어갈 수가 없다는 말입니다.
그럼 PDF의 스트림이 대체 뭘까요..
제가 애용하는 블로그 글 하나 소개드리겠습니다.
https://forensicresearch.tistory.com/4
PDF(Portable Document Format) File Structure Analysis
이번에 분석해볼 파일구조는 PDF 파일 입니다. PDF 파일이란? 우리가 이야기 하는 PDF는 이동가능 문서 형식(Portable Document Format) 의 약자로 Adobe에서 개발한 전자 문서 형식입니다. PDF는 컴퓨터 환경
blog.forensicresearch.kr
여기 글 작성자분이 PDF에 대해서 정말 상세하게 분석을 해놓으셔서 이해가 정말 쏙쏙 되더라구요..
일단 우리는 Stream에 집중해서 볼 것이기 때문에, 그 부분만 보겠습니다. ^_^
일단 PDF는 크게 네가지 구조로 이루어져있는데, Object, File Structure, Document Structure, Content Streams 입니다.
아까 주석에서 Content Streams를 봤었죠? 이 Content Streams는 PDF 문서의 외곽, 그래프 요소들을 묘사하는 명령들을 가지고 있다고 합니다. 그리고 Object는 PDF를 구성하는 요소이구요.
아까 HxD에서 봤는 stream 그것은 Stream Object라는 것인데요, 이건 길이 제한도 없고, 주로 다른 오브젝트로 표현이 불가하거나, 상대적으로 큰 이미지 파일, 또는 페이지 구성 오브젝트(파일 내용)은 이것으로 표현이 된다고 합니다!!
네 이제 조금 분석이 잘 될 것 같네요!
그런데 우연찮게, 분석 중에 고민을 하다가 Crash 파일(Mutation 된 파일)과 원본 파일을 비교해서 분석을 시작해보았습니다. 앞서 PDFStreamDumper를 통해서 분석을 했지만, 석연치 않은 부분이 한 두가지가 아니었습니다.

확인을 해보면, 원본 파일의 Length 부분이 8 0 R로 되어있는 것을 확인할 수 있었습니다.
그래서, Crash 파일과 같이 Length 부분을 8 0 R로 고쳐보았습니다.
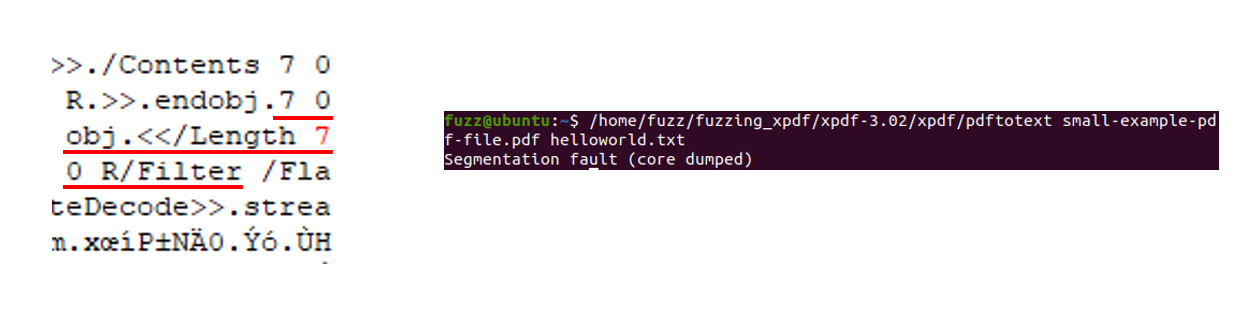
정말 놀랍게도, 같은 오류가 발생한 것을 확인할 수 있었습니다.
그렇다면 대체 8 0 R, 7 0 R 이라고 하는 것이 무엇일까 찾아보아야겠다고 생각이 들어 찾아보았습니다.
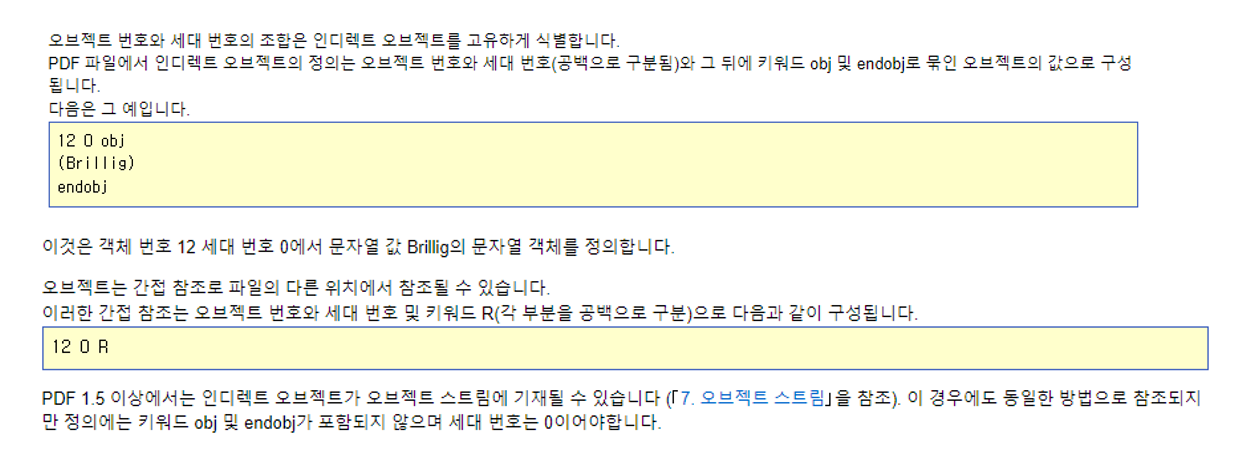
확인해보니 PDF의 오브젝트 번호를 통해서 간접 참조하는 방식이었으며, 위와 같이 선언 및 참조가 가능하였습니다.
그런데 이것을 보고 퍼뜩 한 생각이 지나갔습니다.
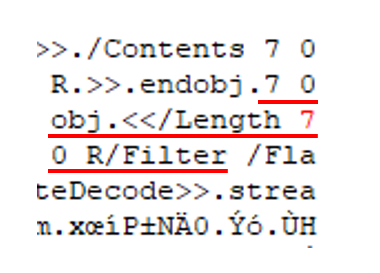
혹시 뭔가 보이시나요? 구문은 아래와 같았습니다.
7 0 R obj <<Length 7 0 R/Filter /FlateDecode>> stream ~~~~~~~ endstream endobj
그렇습니다! 애초에 Object를 7 0 R 로 만들었는데, 7 0 R 오브젝트 안의 Length가 다시 한 번 7 0 R Object를 참조하고 있는 것입니다!
이것이 바로 getObj의 무한 실행을 야기시키는 것이겠지요.
비슷한 조건을 가진 파일로 PoC 제작을 시도해보았습니다.

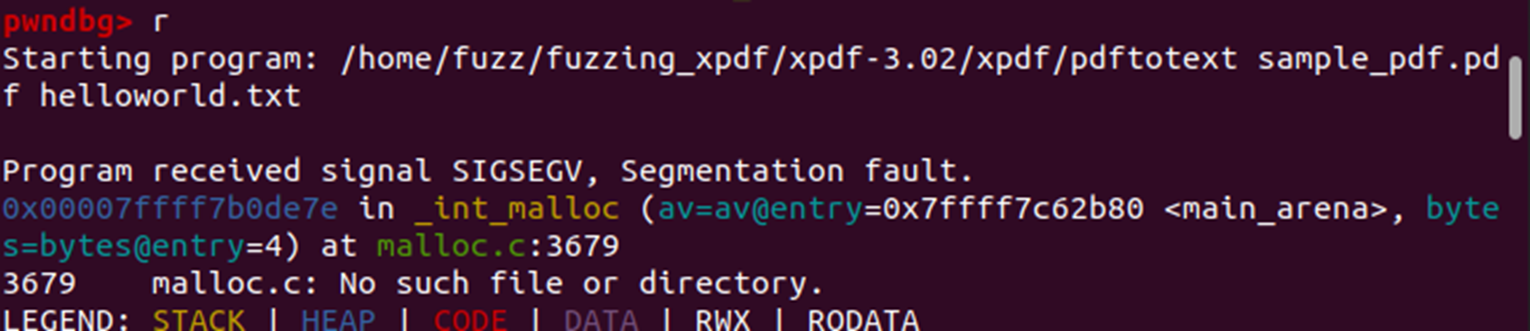
정답이었습니다~ 너무 행복하네요.
어떻게 패치되었을까?
패치된 소스를 확인해보겠습니다.
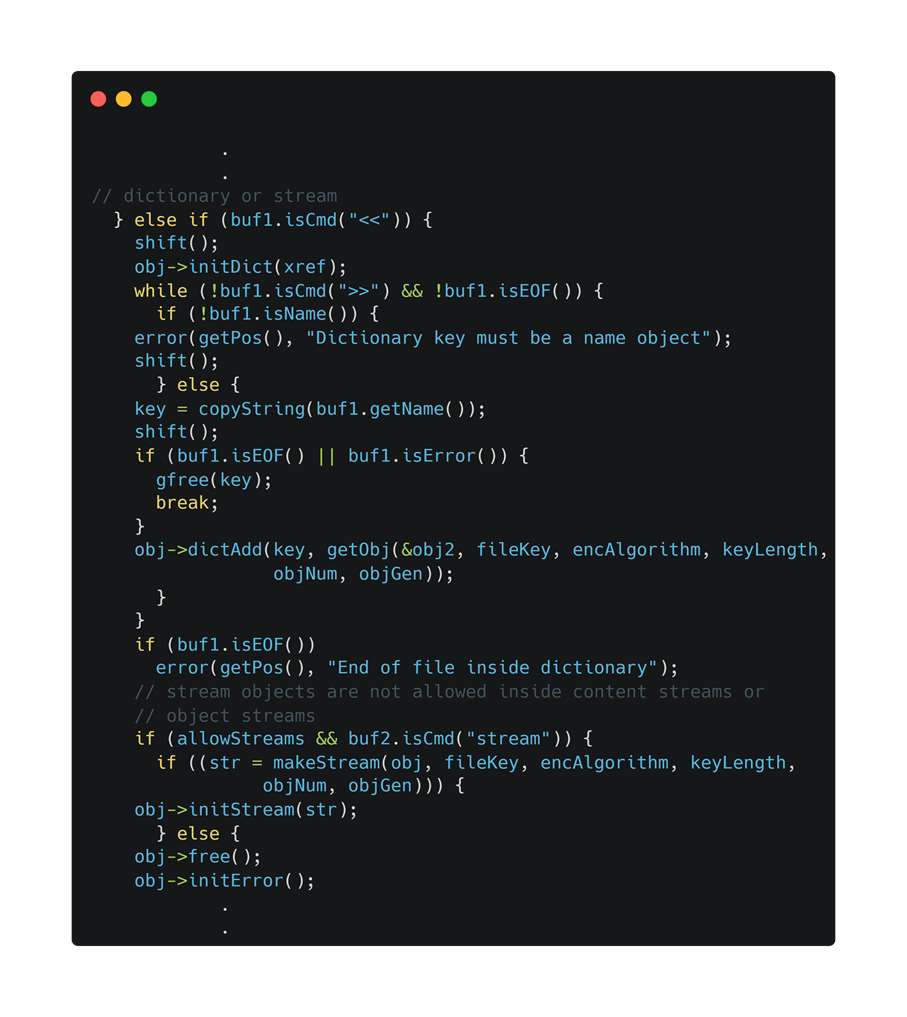
못 보던 RecursionLmit과 simpleOnly, recursion 변수가 if문에 추가되었네요.
분석한 결과에 따르면, Stream을 포함하고 있는 Object가 Length와 같은 요소로 자기 자신을 참조하면 이런 일이 발생하는 것이기 때문에, 해당 if문에 recursionLimit(5000입니다.) 이라는 상수를 추가해서 재귀가 일정 수준 이상 진행되면 아예 exit를 시키는 것으로 패치되었습니다.
다음은 최신 버전에서 PoC를 테스트해봐야겠죠?

네 이렇게, Object가 이미 Parse 되었다고 나오고, Bad Length attribute등 많은 경고문이 추가되었네요.
하지만! 아까처럼 세그멘테이션 폴트는 뜨지 않습니다. 패치가 잘 되었네요~
결론
긴 글 읽어주셔서 감사합니다~
'취약점 > Fuzzing101' 카테고리의 다른 글
| [Fuzzing101] Exercise 2 - libexif (CVE-2009-3895, CVE-2012-2836) (0) | 2022.03.26 |
|---|